So I got invited to another reddit games hackathon despite giving up on the last one. For the last hackathon, I had planned on migrating my mobile game Contagion Mobile to the reddit devvit platform. I made good progress on the backend port of the game, however, I simply did not have time to complete the project and gave up pretty early on. But, I did not stop thinking about the project, or some of the challenges I was facing around the architecture for the backend. In this post, I will go into a problem I have been facing attempting to get a multiplayer realtime game up and running in a serverless environment.
Original Game
In the original game, I had a single ec2 micro instance that all clients connected to. All of the game state was stored in memory, and the single instance performed game calculations, and forwarded updates to the clients.
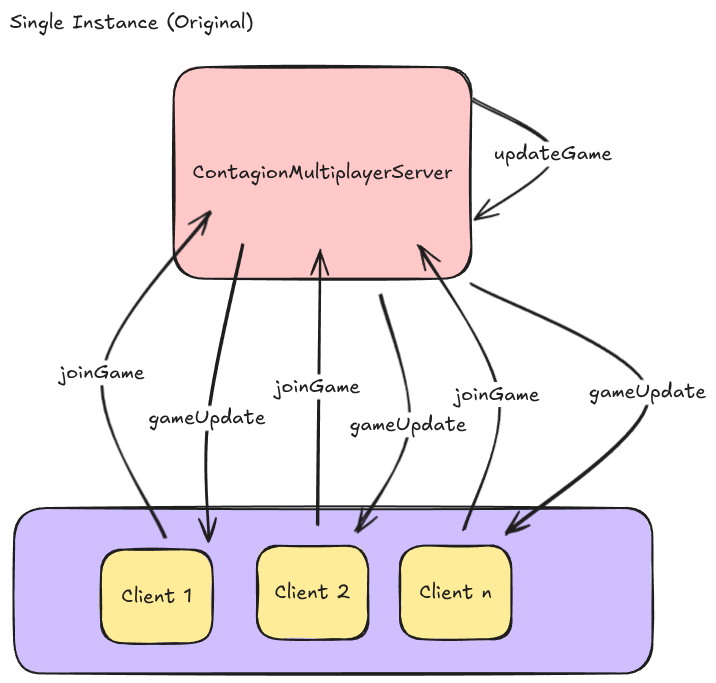
In this type of setup, I did not have to worry about coordinatiing between multiple server instances. The game in essence could be thought of as a singleton that all players are connected to. All data is centrally located on the instance, and there are no external databases. Once the current game is over, or the server shuts down, all data is lost and the server waits for a new user to join to start a new game. There is not even an api to start the game, the game is simply started with a 15 second count down when 1 atleast one player is connected, and a game is not already in progress. In the event that a game is in progress, the newly joined user is added to that game.
This is much different than the architecture used in the reddit devvit apps. In this case, clients are (assumed) to be connected to an array of hosts. These hosts can then share state via a redis instance. So what happens when I attempt to just 1-1 port the backend from a single instance to devit?
Uncoordinated Chaos
As you may have guessed, a simple port resulted in a mess of uncoordinated chaos.
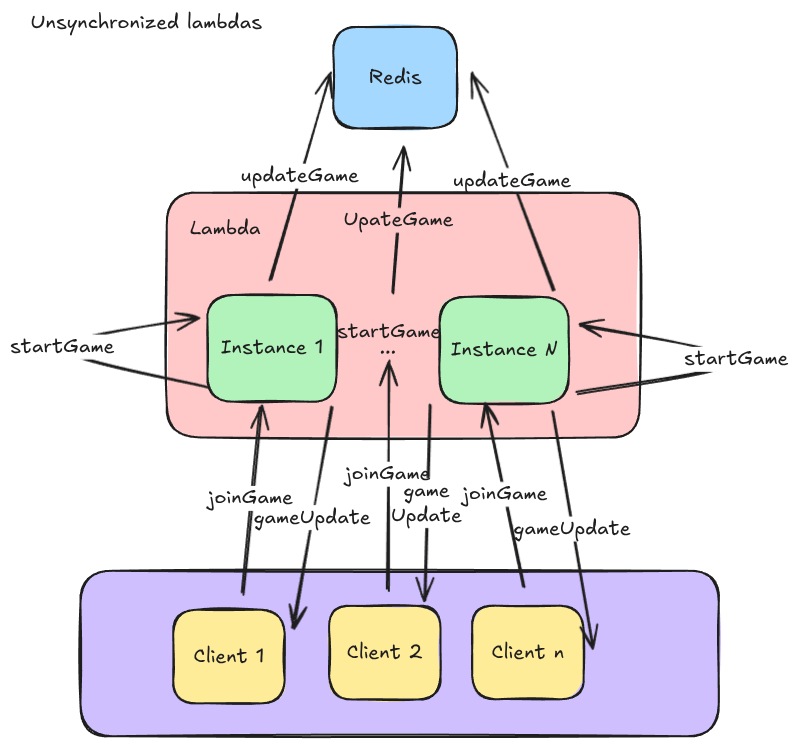
When a client connects, it hits a host and that host starts a game. But there is no guarenttee that you will always connect to the same host, so on subsequent requests, another lambda instance can lead to another game engine starting and updating the game. This becomes an issue when you realize that each game instance will be adding new zombies to the map in parrallel, rapidly cascading into too many zombies being spawned and ever increasing game updates. Basically, we need to ensure that only one game engine is updating the game state at a time.
Leader Follower
To do this, we can introduce the leader follower pattern. In this architecture, we will elect a single instance to run the game engine and perform updates, and subsquent lambda instances would simply read from the game state and send game updates on an interval.
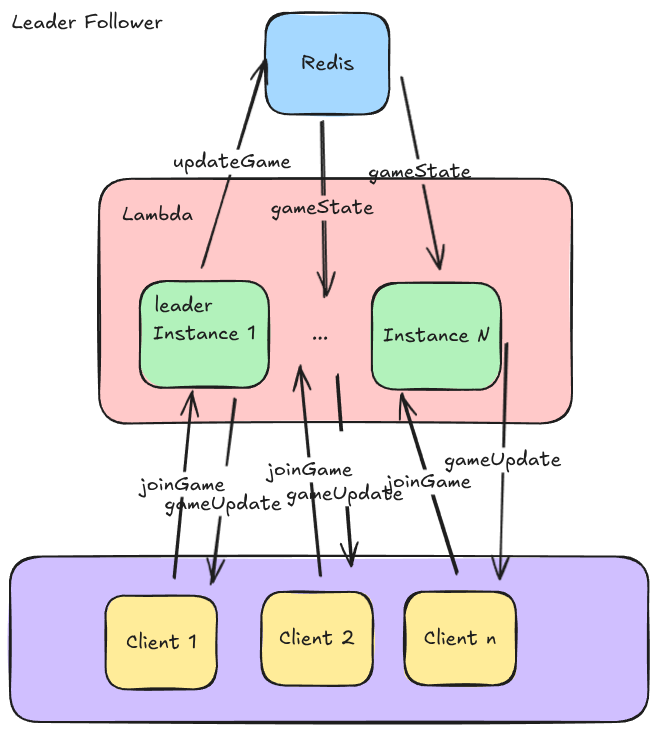
For this, we will keep it simple where the leader is elected by default if a client joins and there are not existing game in progress. Once the leader is elected, it will perform game updates and provide updates to connected clients. Inevitably (if the games any good) when another client joins and hits another lambda instance, that instance will return game updates by reading from the shared game state and sending to the clients. But this leads us to another issue, what happens if the leader lambda instance dies? This is a common occurrence in serverless environments as the managed service cycles through new virtual instances on a periodic basis, sometimes in as little as 15 minute rotations.
Zombie Game
A case of a dead lambda can result in a zombie game where a game is in progress, but is stuck in a non updating state.
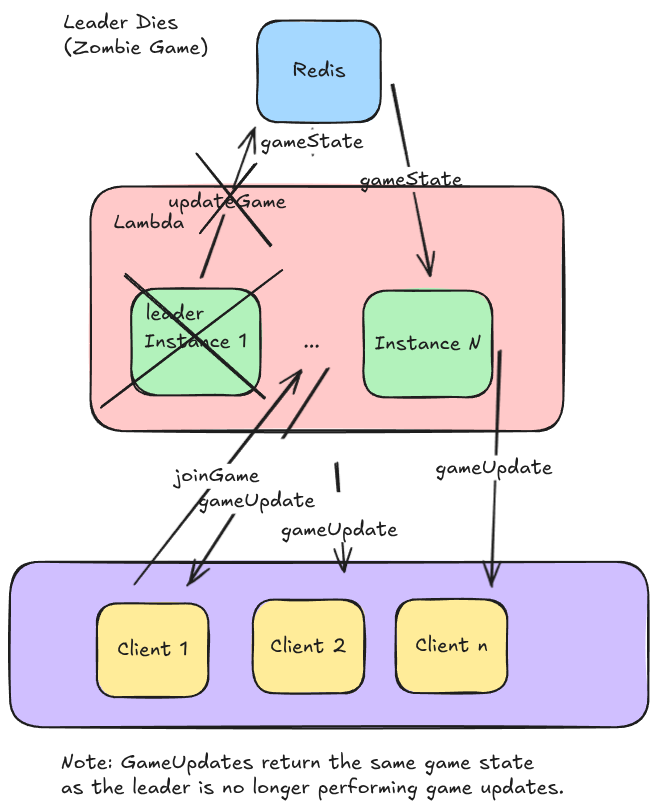
If the leader dies, the followers could still be polling for game updates that never occur. This would result in clients receiving the same game state every update, effectively freezing the game. So how do we mitigate this?
Failover
This is where failovers come in, where we migrate the game engine from the old leader to a new leader.
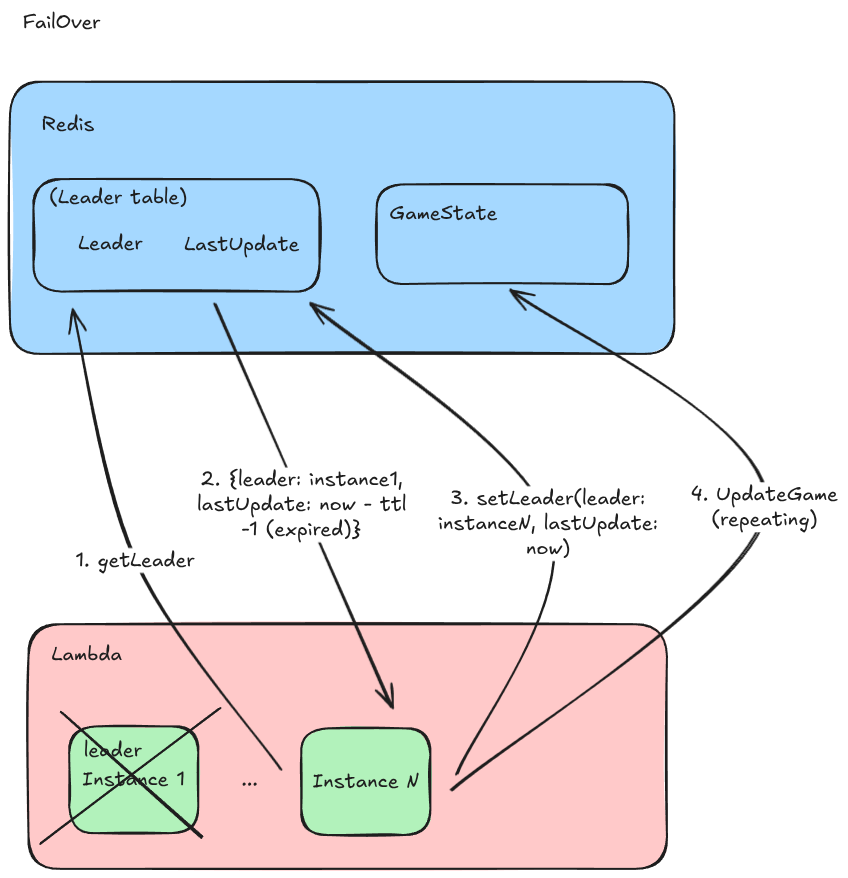
In this case, we will add logic to each of the follower instances that checks a new table in redis to see when the leader last updated the game state. After a expiry period (ttl) of innactivity the next follower to check the record will elect themself the new leader and start the game engine on their instance. This could lead to a frozen period of time where the game is not being updated, but once the new leader is elected the game can continue.
Future, Consensus
The above diagram can result in race conditions where if a leader expires, and multiple lambda instances notice at the same time, then they can both attempt to set themselves as the leader. To guard against this, I plan to have each instance periodically check the leader so that if multiple instances think they are the leader, the next time they check they will defer to the last updated leader and stop their game engine.
What’s next
So I’ve mapped out the issue I was facing and a potential mitigation, now it’s time to implement it. But I am not sure if I will have the time or motivation to actually implement it. This is also all theoretical, I am not sure what issues I will run into when I eventually implement this, or anything that I may have missed. Let me know if you think I’m missing anything, or your thoughts about any of this in the comments. Or if you want to join me in bringing Contagion Mobile to reddit, drop a comment on r/wannawatchmecode.
Keep it swizzy!
J
You’ve made some really good points there. I looked on the internet to learn more about the issue and found most individuals will go along with your views on this website.