Introduction
So I’ve been working on this database I wrote in nodejs that I started almost 4 years ago as a side project. I’m sure your first thought is “Why would you ever do that?”, and to that I say, I wanted to. This project, like many of my others, was just experiment and learning experience. The initial plan wasn’t even to build a database, it was to create a swap cache, like what you see when you check your resource monitor on a mac and see it’s using like 30gb of swap. I’m not going into it now, but if you’d like to learn more about swap caches, leave a comment and I’ll write a follow up.
Anyway, as part of that project, I basically made a json based storage system on top of my file system. On it’s own, I wasn’t sure that swap cache provided any value, but then it clicked that this could be turned into a database really easily. So one saturday afternoon, I created a simple express crud api wrapper on swap cache, and SwapCacheDb was born. After creating the crud api, I knew I needed query support.
Query Schema
I have experience with both sql and NoSql databases (mongodb, dynamodb), but I thought I could do better on the query schema, so I created my own called SwapQuery! The intial schema was not perfect, but was able to do basic queries. If I recall correctly the schema was something like:
{
"=": {
"name": "matchingName"
},
">": {
"age": 10
}
}In the above query, this would match a record with the name equal to “matchingName” and with an age greater than 10. I’m not sure if you can see why this is not a perfect schema, specifically if you want to do querying of objects like below:
{
"=": {
"name": "matchingName",
"job": {
"company": "someCompany"
}
},
">": {
"age": 10,
"job": {
"foundingYear": 1994
}
}
}In this case, what should the query do? Looking at the “=” block, we are checking for a job that has a company of someCompany. But does the “=” apply to only the values in the job object? Or is it apply the match to the entire object? For example, if job always has a foundingYear, if we match the entire object it will always fail. This confusing behavior made it clear to me that this was not an ideal schema, but it works somewhat and I don’t have a better solution, so I moved on (for now).
2 years pass
So time went by, I got really busy with work and got promoted, and took on more responsibility. My pet projects were on the back burner, and I spent my free time just decompressing. That is until around 2 years later in 2024…

One day I decided I would take another look at swap cache db. I was actually quite impressed with the work I had done. In addition to the core crud api for the db, I created a serialization library supporting encryption, as well as a throttling library. I did do some load testing and was getting some good results, I was seeing up to 8k TPS, although these tests turned out to be improperly setup. Regardless, I realized that I was the only one who ever used this and I was reminded of a friend of mine who used to work on dynamo db. So I reached out to him to see if he would want to test it and he was interested. But how would I share it with him?
Deploy to AWS
I decided that providing him with the libraries themselves and having him set it up was likely not a reasonable ask. Then I got to thinking, how can I get this deployed and ready for production, and just provide the db information to my friend and he can use it as a SaaS. I got really excited about this, and planned out how I was going to do this.
My main concern was the security of it, how would I protect the api’s from unauthorized access. This turned out to not be a big issue, I ended up just creating an authorization middleware that I applied to each api, and hardcoded in code (I know this isn’t good) some very long api keys parsed from the header. This accomplished my goal, and I was ready to get up and running.
At this point, I wanted to get it up and running as quickly as possible. So I skipped doing IaC and just manually created an ec2 instance. If I recall correctly I just scp’d the pre-built the packages to the host. From there I installed all of the dependencies (npm, nodejs etc) and manually started the db server. At this point, everything was ready to go. So I created a user guide, and provided this along with an api key to my buddy to test.
Testing went ok, I got good feedback and it actually worked. But the db was not very robust, at the time it only supported crud operations, and subpar query support. I knew if I wanted a useful database, I would need some mechanism for users to query for data effectively. Although I knew I needed to add better query support, the project was becoming more difficult to maintain, so I focused on fixing this instead.
Migrate to SwizzyWebService
At this time, I was live streaming a lot of WannaWatchMeCode where I was building random software live on twitch. One of these experiments, SwizzyWebService was in it’s early stages of development and I was building it to address some of the maintainence issues I was having with SwapCacheDb. One of the contributing factors to SwapCacheDb’s maintainence issues had to do with state/dependency management. I had core components that needed to be shared between different routers in express, and it always scares me to depend on what are effectively singletons in js. So dependency injection became a core part of SwizzyWebService as can be seen below:
// State
interface GetControllerState {
cache: Cache<any, any>;
queryEngine: SwapQueryEngine;
}
export class QueryController extends QueryController<
ISwapCacheDbWebRouterState,
QueryControllerState
> {
...
// Controller method
protected async getInitializedController(
props: IWebControllerInitProps<ISwapCacheDbWebRouterState> & {
state: GetControllerState | undefined;
},
): Promise<WebControllerFunction> {
const getState = this.getState.bind(this);
const logger = this.logger;
return async function GetFunction(req: Request & KeyBody, res: Response) {
const { key , tableName, query} = req.body;
const { cache, queryEngine } = getState()!; // State
try {
const qRequest = ...;
const values = cache.all();
const matches = values.filter((val) => queryEngine.matches(val, query));
// other logic, validation, send response
res.send(...);
return;
} catch (e: any | SwapCacheDbException) {
// error handling
}
res.status(500);
res.send();
};
}
}Migrating to SwizzyWebService ended up being pretty straight forward, and the benefit was huge. Depenbencies are now always guaranteed to be consistent between each route, and code blocks were seperated out into properly isolated components. With the addition of Swerve, I also had a standard way of injecting arguments into the service at startup, and a config schema for managing the service. Not to mention, dynserve (now swerver) to run it dynamically through a web portal.
// web-service-config.json
{
"port": 3050,
"services": {
"SwapCacheDb": {
"packageName": "@swizzyweb/swap-cache-db-web-service",
"port": 3051,
"tableName": "secScanner",
"forceNoAuth": true,
"requestSizeLimit": "50mb"
}
}Seperation of concerns
Despite migrating to SwizzyWeb, there was still a lot of logic going on in the web service. I wanted to reduce scope of the api to only calling depenedncies and returning a response. At this stage, all of the logic was written in the controllers themselves. This mostly consisted of calling SwapCache directly, and in the case of querying perform the query filtering. This is probably fine, but it makes testing more difficult since I cannot just directly hit the db logic, but rather have to trigger it through api requests.
Enter SwapCacheDb package
To address this, I pulled out all of the logic into a seperate package, swap-cache-db. This package provides a facade that handles all of the db logic. By pulling this logic out, I was able to write tests to test the db logic in isolation. Furthermore, this gave me a lot more flexibility in modifying the database logic. Now instead of modifying or adding controllers to support different functionality, I can just extend a class or re-implement the core db interface and inject it as a replacement. No need to touch the web service layer at all. Now our contorller can basically just be:
// State
interface GetControllerState {
db: ISwapCacheDb<any, any>;
}
export class QueryController extends QueryController<
ISwapCacheDbWebRouterState,
QueryControllerState
> {
...
// Controller method
protected async getInitializedController(
props: IWebControllerInitProps<ISwapCacheDbWebRouterState> & {
state: GetControllerState | undefined;
},
): Promise<WebControllerFunction> {
const getState = this.getState.bind(this);
const logger = this.logger;
return async function GetFunction(req: Request & KeyBody, res: Response) {
const { key , tableName, query} = req.body;
const { db } = getState()!; // State
try {
const qRequest = ...;
const values = db.query(qRequest);
// other logic, validation, send response
res.send(...);
return;
} catch (e: any | SwapCacheDbException) {
// error handling
}
res.status(500);
res.send();
};
}
}But it’s just a table
We’re in a good spot now, we’ve addressed some of the maintainability issues with SwizzWeb, but theres one issue, this isn’t a db, it’s a table. Usually databases allow you to create multiple tables, but with this one that’s not an option at this point. For now I decided this was acceptable, in my mind, tables are the pre-requisites for databases, it is a many to one relationship. So the logic I was writing for single tables is not throw away work, and I can maintain routing between tables via another layer or api. What really interested me though was how I can implement sharding for a table, so I did that.
NoSql is more than json storage
Theres been this trend I see online where people recommend postresql for everything, including unstructured json data. The argument is basically that postgres is amazing and the json search is good. But storing json and being able to query it misses one of the crucial points of no sql databases, horizontal scaling. I’m sure theres some argument that sql databases scale horizontally, which they do for read replicas, but historically writes occur on a single instance constraining that node to vertical scaling only. This is a fundamental reason why one might chose nosql, it can scale horizontally distributing both reads and writes to seperate hosts and partitions. Of course, SwapCacheDb did not support this yet, so I added it…
Horizontal Scaling
In order to support scaling, I needed an entry point that clients would call to get the data they needed. Theoretically I could create a thick client that knows all shard address and does the routing themselves, but I have an openapi spec for generating the client accross any language, so to implement custom clients for all possible programming languages was not worth the time IMO. So then I chose to create a routing web service that would get the data from the proper location. But how do I know which instance holds which data?
Metadata cache
One option is for the router to determine where to store data and maintain a record of the key mappings to target shard. After very little thought I threw this idea out mainly because this would double the amount of key data we are storing, and router service storage capacity would scale with the number of records in the database. If stored on disk, this would also increase latencies and reduce throughpout.
Consistent hashing
The idea I ended up going with was to use consistent hashing. I already implemented hasing for the keys for storing data to disk, so I could do something similar here. The idea is that we would has the keys in a consistent way. This means that given the same raw input key, you will always get back the same hash value. The hash value also has to be unique per record to avoid collisions, where a collision just means that two different keys hash to the same value. If collisions occur, then you can potentially be overwriting incorrect records unintentionally. I realized that there were some potential collision issues with my existing hashing strategy, so I decided to make a new library to serve my needs, Hashbrown. Hashbrown serializes each key to a string in a format to prevent hash colisions, then hashs that string via sha256 producing a 256 bit hex encoded string.
Getting the correct host
Now that we have consistent hashing, we can consistently get a unique hash for each record. From there, I created routing logic that determines the proper end host by checking the prefix of the hash. How this works is that all hashes are base64 encodded, which means that the only supported characters in the output are 0-9 and a-f. So the configuration becomes something like:
[{
hashStart: 0,
hashEnd: 1,
host: http://1.somehost.com/db
},
...,
{
hashStart: e,
hashEnd: f,
host: http://n.somehost.com/db
},]We have the route map setup, now how will the client use this? I came up with 2 options, and implemented both.
SwapCacheDbMetadataWebService
The metadata web service was the first solution I built, despite it not being the most common pattern. The idea to create the metadata web service came from my work on lustre. Lustre is a distributed file system that performs routing in this manner, so I figured I’d see how it would perform in my system.
So what do I mean by a metadata web service? I guess one way of visualizing this is to think of it like a secretary. The metadata web service doesn’t directly give you the data you need, but rather where you can get that data. For example, if you are going to a dr’s appointment you check in with the secretary, the secretary gives you the room number of the doctor and the doctor performs your exam and gives you the results. The secretary just redirects you to where you need to be and doesn’t do any of the heavy lifting.
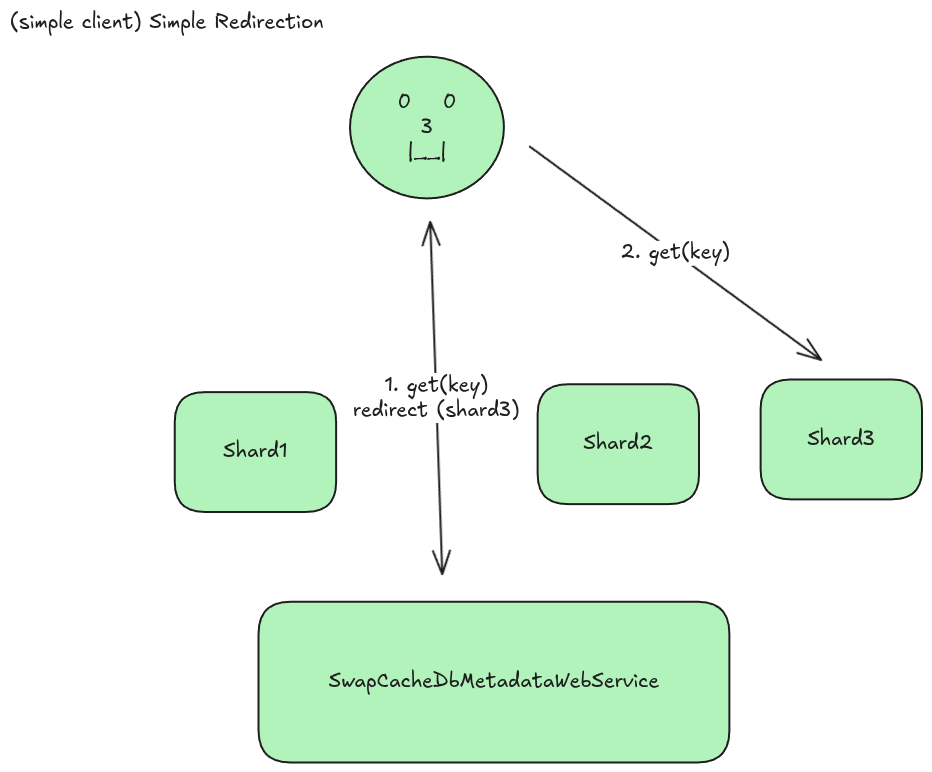
As you can see in the diagram above, SwapCacheDbMetadataWebService is the first thing the client talks to, then an http redirect is returned to the proper shard to get data from. The client then actually gets the data directly from the shard.
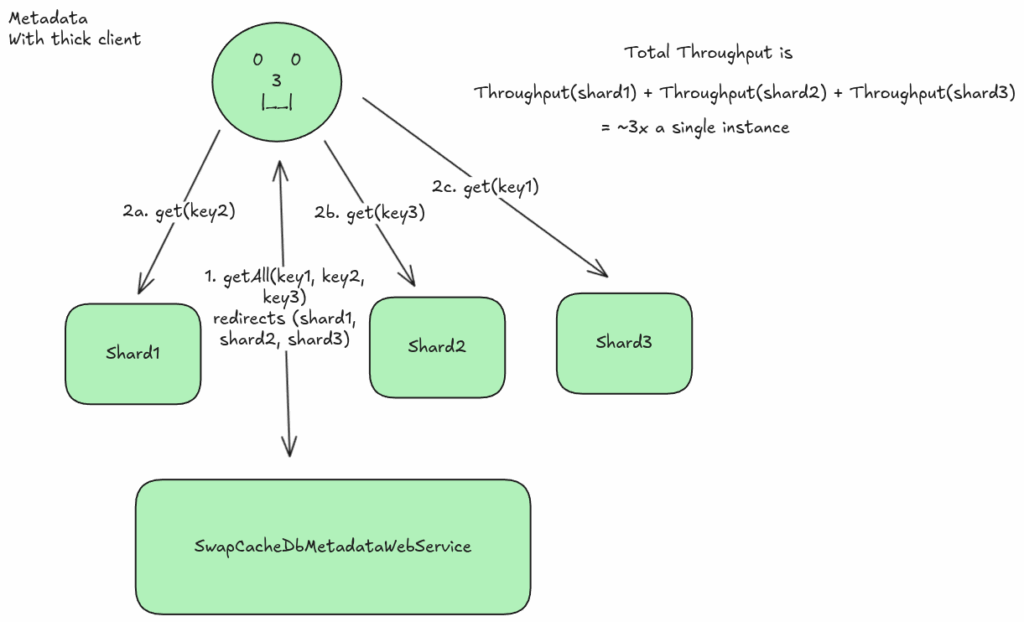
This pattern adds a performance improvement similar to lustres where parralel calls to different shards results in a total throughput of the sum of each hosts throughput (as shown above). The pitfall of this approach is that it requires the sharded tables to be accessible from the client. This means that to protect the shards from unauthorized access, we will need to have an additional layer to verify the clients request. This could open up the shards to DDoS risk, and is another endpoint that can be exploited. Futhermore, with the simple redirection apporoach, batch and query operations would be more difficult if not impossible. This lead me to the second approach, creating a “proxy” based router.
Proxy based SwapCacheDbRouterWebService
The proxy based approach is a more typical approach to accomplish the shrading behavior I need. In this approach, the router takes the request from the user, and calls the shards itself to retrieve the data.
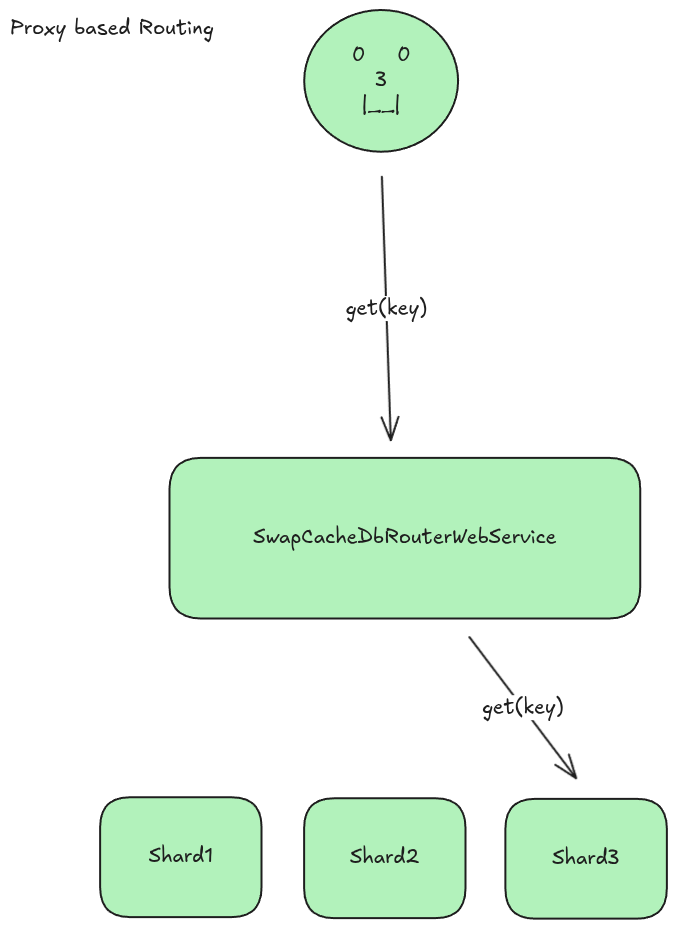
Once the data ius retrieved, it is aggregated (for batch or queries) and returned from the proxy to the client.
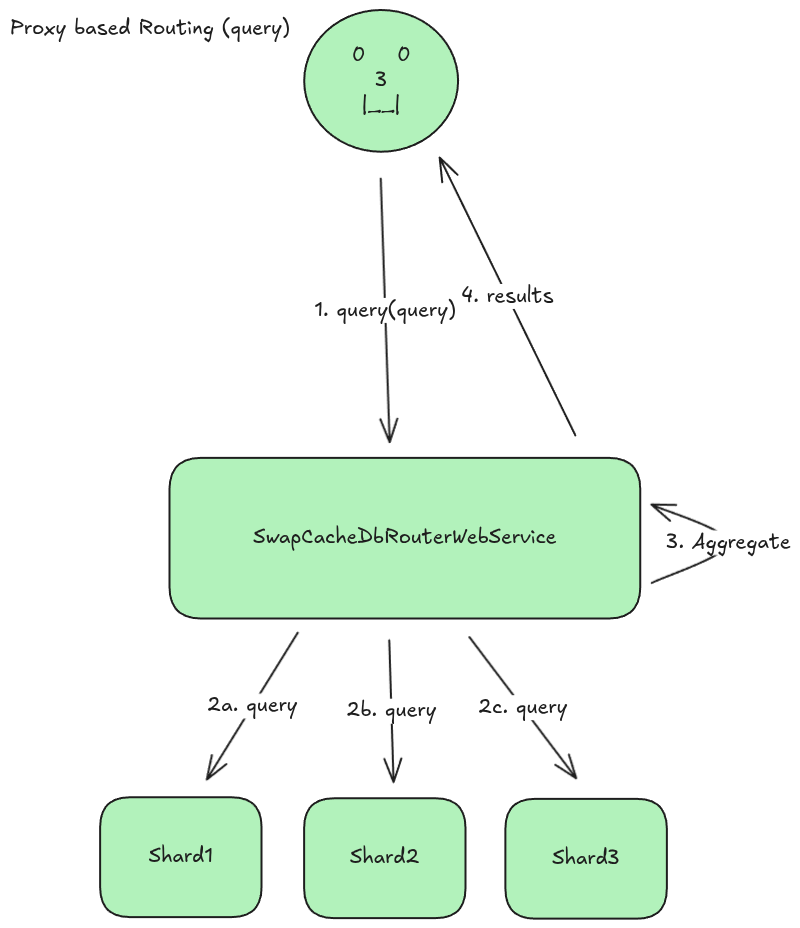
This approach gives us the benefit that the shard tables can be private to the backend network and not accessible to clients or attackers. The tradeoff is that the proxy router now becomes the bottleneck and takes on additional load. This may or may not be a big issue considering most of the time spent by the router is waiting for io to complete, but load testing is needed to determine the actual impact.
As a side note, I am working on pulling out some of the request body parameters required for routing into the either the query string or maybe a header so that the router does not need to deserialize the body as part of routing. This could save on the compute that would be required to read and deserialize the request as it could just be piped into the request to the shards. But this is a topic for another day.
Write Ahead Logging (WAL)
After I had accomplished getting sharding to work, I started thinking about how I can scale the database up and down at runtime. The solution I implemented relied on a fixed configuration that was used as the routing table, and setting up the individual tables. But to modify this at runtime is not possible (right now).
So this got me to thinking about data consistency, disaster recovery, and redistribution of data on scaling. For this I decided I needed a way to track record modifications so that in the event I scale out (copying a portion of one shard to a new shard). I would need a write ahead logger where I basically just write the key, value, and operation to a log file prior to persisting the record to disk. This way, if a record fails to be written to disk, we can basically replay the WAL changes back to the db to record those changes. This also lends itself nicely to rebalancing.
Rebalancing (planned for the future)
For rebalancing, the idea is that I would take a snapshot of the existing shard, then restore it on the new shard. But there is one issue with this in that if records change durinng the snapshot, the restored shard will be missing those modifications. So as a seconds step, we can simply replay the wal log on the secondary shard to get any updates that occurred while the snapshot was being taken. This is the planned approach, but I have not implemneted it yet.
SwapCacheDbTable and SwapCacheDb
Let’s get back on track. As we’ve established, SwapCacheDb at the time was basically just a single table. So I ended up forking the current state into a new package called SwapCacheDbTable, and a supporting SwizzyWeb service named SwapCacheDbTableWebService. I also did the same for the open api schema and basically have a standalone copy of the tables implementation.
I then went to work on updating SwapCacheDb to actually be a multi table database. For this I basically had the same API’s, but added an additional tableName field to determine which table a user wanted to use. Under the hood, the SwapCacheDb implentation aggregates SwapCacheDbTables and routes the request to the proper tables following the traditional api. In this sense, SwapCacheDb just acts as a router to the underlying tables. After all of this, I now have a multi table database, mission accomplished! But querying still sucks.
SwapQuery New Schema
This articles pretty long already, but I brainstormed a new schema for the database that addressed some of the shortcomings of the original design. This deserves a post on it’s own, but just know that it’s a lot better. Now that I have a proper querying language, I had a reason to actually test the query api’s. So I did some manual testing, then created some load tests to see how it performed under load.
Queries… Block… Everthing!
What I found when I performed my load test would have made a lesser dev throw it all away, but me, I was excited by the abismal performance of my queries. Sure querying a 5k record database took 9 seconds, and sure every single api is blocked by a long running query. But, I finally hit some real world edge cases that give me the opportunity to do some low level magic.
You see, nodejs has an event loop that basically basically performs synchronous logic in a blocking manner. That is, synchronous code will block the event loop from processing any other logic until it either finishes, or hits an synchronous part of code that will run in the background unblocking the event loop to pickup new tasks.
The issue I was facing is that the underlying SwapCache data layer was intentionally made entirely synchronous. This synchronous nature means that every request that hit’s the SwapCache will block the event loop until completion. This is fine for crud operations, as each record is a relatively small amount of data. But this crumbles on long running queries, where every record needs to be read from disk, deserialized, decrypted (if encryption enabled), and then filtered before being returned to the client. I knew I needed to address this as the database is basically useless if querying is needed.
Enter SwapCacheAsync
My initial thought, which I was unsure about, was to fork SwapCache into a new SwapCacheAsync library, where instead of using sync operations I would use their async variants. So I did this and it wasn’t very difficult, I just had to update the interfaces and implementations to return promises, and update the file operations to use fs/promises vs the standard fs library in SwapCache. Then I had to update SwapCacheDb to await all calls to SwapCache. I did this in a way where I can use dependency injection to chose which implementation to use at runtime. The dependency injection decision turned out to be amazing…. because the async swap cache was actually worse then the sync version. Thankfully, swapping between the two implementations was basically a one line change, which I ended up making configurable through the swerve configuration so you can configure it with an argument on startup with no code changes.
Why was it slower?
I didn’t dive too deep on this one, but what I beleive was happening was that since the IO was so small, the cost of context switches between async operations outweighted the non blocking behavior. So it was time to brainstorm another solution.
Thread Workers and Process Management
I realized I was hitting the limits of the single threaded event loop in nodejs, so I decided I would branch out into parrallel computing. I had two options in this case, I could either use thread workers for multi threading, or I could spin up new processes to perform work in the background. I have previously worked with pthreads, sse, cuda, and some other stuff in raw c code before, but only ever dabbled in node.js multithreading. Even with my limitted context, I knew that the thread worker structure in node.js was fairly barebones, and I would have to do some heavy lifting to get what I needed done. So I ended up building an initial implementation of a thread worker directly in SwapCacheDb to figure out what I actually needed. Then I observed some patterns that I (or you) could re-use for other projects.
Quirk to the rescue
This lead me to build quirk, a parrallel execution library for typescript engines. Quirk is a library basically provides you with an interface for making worker implementations, and managers that allow you to invoke those workers. There are several implementations for this so far, like a manager that creates a new thread per job, or a quirkpool that maintains a collection of threads and re-uses them for incoming requests. Quirks main benefit is that it standardizes and abstracts the inter thread / process communication to handle the lifecycle of jobs, and maintain distribution of jobs to available threads / processes. Quirk became the answer to my query blocking problem, and resulted in an up to 400x improvement in get latency while under high query load. This of course took some time to test and debug as the first few versions had some bottlenecking bugs triggering great learning experiences, but that’s for another day. Leave a comment if you want me to open source this.
Performance
I imagine the first thing you wanted to see was how well this database actually performs, so let’s get to it.
For these tests, I ran a drill load test with 16 cores from my homelab to my local laptop over ethernet on my private home network. The connection from my homlab goes through a 1gb switch, to a 2.5gb router, to a second 1gb router, then to my laptop. So theoretically we are looking at up to 1gb throughput max, however we don’t get anywhere close to saturating that. The database was running on my Framework laptop with a 8c 16vcpu system with 96 GiB of ram (I know, it’s a beast). The test was also run with encryption disabled, will have to have a dedicated post for more tests, but let’s get to the results for now.
Put / Get / Delete Performance
Put item Total requests 80000
Put item Successful requests 80000
Put item Failed requests 0
Put item Median time per request 3ms
Put item Average time per request 3ms
Put item Sample standard deviation 1ms
Put item 99.0'th percentile 8ms
Put item 99.5'th percentile 8ms
Put item 99.9'th percentile 9ms
Get item Total requests 80000
Get item Successful requests 80000
Get item Failed requests 0
Get item Median time per request 2ms
Get item Average time per request 3ms
Get item Sample standard deviation 1ms
Get item 99.0'th percentile 6ms
Get item 99.5'th percentile 6ms
Get item 99.9'th percentile 7ms
Delete item {"key":{{ item }}} Total requests 80000
Delete item {"key":{{ item }}} Successful requests 80000
Delete item {"key":{{ item }}} Failed requests 0
Delete item {"key":{{ item }}} Median time per request 2ms
Delete item {"key":{{ item }}} Average time per request 2ms
Delete item {"key":{{ item }}} Sample standard deviation 1ms
Delete item {"key":{{ item }}} 99.0'th percentile 5ms
Delete item {"key":{{ item }}} 99.5'th percentile 6ms
Delete item {"key":{{ item }}} 99.9'th percentile 7ms
Time taken for tests 42.8 seconds
Total requests 240000
Successful requests 240000
Failed requests 0
Requests per second 5604.35 [#/sec]
Median time per request 3ms
Average time per request 3ms
Sample standard deviation 1ms
99.0'th percentile 7ms
99.5'th percentile 8ms
99.9'th percentile 9ms
These test results really surprised me. I was pleasently surprised with the ~5600 tps and 9 ms p99.9 latencies. ChatGpt says this is within similar ranges as mongo db and other popular databases, so I’m kind of stunned I was able to achieve this with a nodejs db. Now let’s move onto queries.
Query performance (5k records)
Query item Total requests 3200
Query item Successful requests 3200
Query item Failed requests 0
Query item Median time per request 166ms
Query item Average time per request 180ms
Query item Sample standard deviation 73ms
Query item 99.0'th percentile 373ms
Query item 99.5'th percentile 424ms
Query item 99.9'th percentile 639ms
Time taken for tests 37.3 seconds
Total requests 3200
Successful requests 3200
Failed requests 0
Requests per second 85.74 [#/sec]
Median time per request 166ms
Average time per request 180ms
Sample standard deviation 73ms
99.0'th percentile 373ms
99.5'th percentile 424ms
99.9'th percentile 639ms
So querying was noticable less performant. But that’s to be expected since literally every record needs to be retrieved and processed. Even though this is much lower performance than crud operations, 180 ms average latency is not bad, although the tailing latencies are much higher. And 85.74 tps means that quirk is performing effectively. If you do the math with average latency, the tps should only be < 10 tps, but quirk is handling these in parrallel increasing throughput more than 8x, big win! This may be a surprise to you, but I am proud of these results and IMO they are good enough. This is a nosql database after all, which are well known to be much slower than sql, just look at dynamodb’s absurd scan latencies. The intention of this db is to act more as a key value pair store, which gets sub 10ms latencies, and querying is more of a nice to have.
Query and Get/Put/Delete in parrallel (Quirk)
For this test, I increased the number of queries being done, and ran the query test in one terminal window and the get/put/delete in another terminal (both on homelab). The Get/Put/Delete requests went to the benchmark2 table, and queries were done on the benchmark table. The Get/Put/Delete results were:
Put item Total requests 80000
Put item Successful requests 80000
Put item Failed requests 0
Put item Median time per request 5ms
Put item Average time per request 5ms
Put item Sample standard deviation 2ms
Put item 99.0'th percentile 12ms
Put item 99.5'th percentile 12ms
Put item 99.9'th percentile 14ms
Get item Total requests 80000
Get item Successful requests 80000
Get item Failed requests 0
Get item Median time per request 4ms
Get item Average time per request 4ms
Get item Sample standard deviation 1ms
Get item 99.0'th percentile 9ms
Get item 99.5'th percentile 10ms
Get item 99.9'th percentile 11ms
Delete item {"key":{{ item }}} Total requests 80000
Delete item {"key":{{ item }}} Successful requests 80000
Delete item {"key":{{ item }}} Failed requests 0
Delete item {"key":{{ item }}} Median time per request 4ms
Delete item {"key":{{ item }}} Average time per request 4ms
Delete item {"key":{{ item }}} Sample standard deviation 2ms
Delete item {"key":{{ item }}} 99.0'th percentile 9ms
Delete item {"key":{{ item }}} 99.5'th percentile 10ms
Delete item {"key":{{ item }}} 99.9'th percentile 12ms
Time taken for tests 70.3 seconds
Total requests 240000
Successful requests 240000
Failed requests 0
Requests per second 3413.38 [#/sec]
Median time per request 4ms
Average time per request 5ms
Sample standard deviation 2ms
99.0'th percentile 11ms
99.5'th percentile 12ms
99.9'th percentile 13ms
The results of the crud operations was another pleasant surprise, p99.9 only increased by 4ms! This was a huge win that came from adding quirk. As I mentioned, quirk was not perfect at first. In earlier versions of quirk, I was seeing basically no improvement, so to see this was a good feeling. The next section on the pre-quirk performance will show you what I’m talking about
Query item Total requests 16000
Query item Successful requests 16000
Query item Failed requests 0
Query item Median time per request 171ms
Query item Average time per request 191ms
Query item Sample standard deviation 78ms
Query item 99.0'th percentile 444ms
Query item 99.5'th percentile 485ms
Query item 99.9'th percentile 573ms
Time taken for tests 192.9 seconds
Total requests 16000
Successful requests 16000
Failed requests 0
Requests per second 82.96 [#/sec]
Median time per request 171ms
Average time per request 191ms
Sample standard deviation 78ms
99.0'th percentile 444ms
99.5'th percentile 485ms
99.9'th percentile 573ms
The query load test ran for a signicantly longer amount of time than the other test, so the effect of the Get/Put/Delete test only impacted this test for a fraction of the time it ran. But figured it’d be good to provide anyway, perhaps the p99.9 captures the high end of the latencies caused by the other load test.
Blocking query performance
Of course, I also want to highlight the improvements from adding the quirk implementation in v0.7.0 of SwapCacheDb. The following test was run with 16 threads on the querying load, and 16 threads on get/put/delete running SwapCacheDb v0.6.5.
Below is the put item load test, this was started after the query load test was run.
Put item http://192.168.0.155:3005/db 200 OK 9823ms
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Error connecting 'http://192.168.0.155:3005/db': reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Ipv4(192.168.0.155)), port: Some(3005), path: "/db", query: None, fragment: None }, source: TimedOut }
Put item http://192.168.0.155:3005/db 200 OK 2356ms
Put item http://192.168.0.155:3005/db 200 OK 2373ms
Put item http://192.168.0.155:3005/db 200 OK 2365ms
Put item http://192.168.0.155:3005/db 200 OK 2445msAs you can see above, the query calls completely blocked the put api calls so bad that it resulted in complete request failures. Below you can see that the queries continued to run, but have significantly lower performance than after adding quirk.
Query item http://192.168.0.155:3005/db/query 200 OK 1149ms
Query item http://192.168.0.155:3005/db/query 200 OK 1150ms
Query item http://192.168.0.155:3005/db/query 200 OK 1151ms
Query item http://192.168.0.155:3005/db/query 200 OK 1152ms
Query item http://192.168.0.155:3005/db/query 200 OK 1153ms
Query item http://192.168.0.155:3005/db/query 200 OK 1155ms
Query item http://192.168.0.155:3005/db/query 200 OK 1156ms
Query item http://192.168.0.155:3005/db/query 200 OK 1158ms
Query item http://192.168.0.155:3005/db/query 200 OK 1159ms
Query item http://192.168.0.155:3005/db/query 200 OK 1163ms
Query item http://192.168.0.155:3005/db/query 200 OK 1166ms
Query item http://192.168.0.155:3005/db/query 200 OK 1171ms
Query item http://192.168.0.155:3005/db/query 200 OK 2393ms
Query item http://192.168.0.155:3005/db/query 200 OK 1251ms
I didn’t even bother to complete the tests, it’s painfully obvious that this is an issue, and thankfully quirk fixed it!
Future
So what’s next? I have a ton of ideas on where to go from here.
Full Database Sharding / SwapCacheDbFacade
So I have sharding implimented for indiviual tables, but I need to consider how I would do this for an entire database. For this I am considering making the tables in SwapCacheDb remote, as in SwapCacheDb will have SwapCacheDbTable facades that under the hood actually make api calls to standalone SwapCacheDbTable web services. This way the db api would not have to worry about sharding the tables themselves.
WAL management
During load testing on DigitalOcean I found that the WAL was increaseing at a rapid rate, causing the disk to become almost full. I need to implement some logic to maintain the size of the wal, and offload it to a secondary data store to keep the table hosts disk space down. I will also need a way to distil the wal at certain points so I am able to truncate the logs. What I am thinking is consolodating them into checkpoint snapshots after some time, and removing the old wal.
Scaling and Rebalancing
I mentioned this above, but scaling and rebalancing at runtime seems to be a pretty important feature to get SwapCacheDb production ready.
Backups
No one wants a database you can’t backup. Nuff said.
Management Portal
Right now everything is managed via the swerve configuration. With swerver, you can currently spin up instances via the web ui. But I want to create a management portal specifically for SwapCacheDb so that database setup and management is safer and easier to do.
Encryption Management
Theres a decent amount of work to do to make encryption more flexible. Right now the encryption key is stored on host and there is no identifier in records to track which encryption key was used to encrypt the record. This becomes a problem if the key ever needs to be rotated, as the previous records will still be encrypted with the old key, so reading that record would result in an exception during decryption. I am brainstorming the proper approach to this, but the approach I am currently exploring is storing an identifier with each record that indicates which encryption key was used. This would allow me to use the correct key at runtime to decrypt the records. For key rotations, we could also decrypt records with the old key and re-encrypt with the new key. Once all records are re-encrypted, the old key can be safely deleted.
Wrapping up
So there you have it, my journey building SwapCacheDb in typescript! I hope that this can motivate you to spend some time building out the things you want to build. Many might say that it’s silly and a waste of time to build your own database. But I say coding is never a waste of time. Every line of code you write is an experience and learning opportunity that will make you a stronger engineer.
Sure you can read a book, or an article and know the buzz words, or even explain the theory. But have you ever tried it before in practice? Have you ever blocked an event loop so bad that your service no longer accepts most requests? You may know what consistent hashing is, but have you ever failed to implement it then fix it? These are all things that I learned on my journey that started with me staring at the process manager on my mac. I’ll leave you with this, the next time you have a silly, redundant, or complex idea, just build it because you can 😉 .
Just never stop building,
J