If you’ve read any of my other articles, you’ll know that I created SwapCacheDb, a Database written in typescript. As the project matured, I realized I wanted to implement a solution to horizontally scale out to multiple hosts to acheive (potentially) higher throughout and distribute storage to multiple instances. After all, one of the biggest benefits of NoSql databases over Sql databases like Postgresql is that they support horizontal scaling beyond read replicas.
Where the records at?
In order to support horizontal scaling, I would need a way to determine which host stores what data. I would need to have some sort of unique characteristic for each record that could be used to partition the data to each of the different shards of the database. Each record in the database must have a unique key, so I can queue off of that to determine the hosts. Then each host would be responsible for storing a range of keys and requests for those records would be retrieved or stored on the corresponding host.
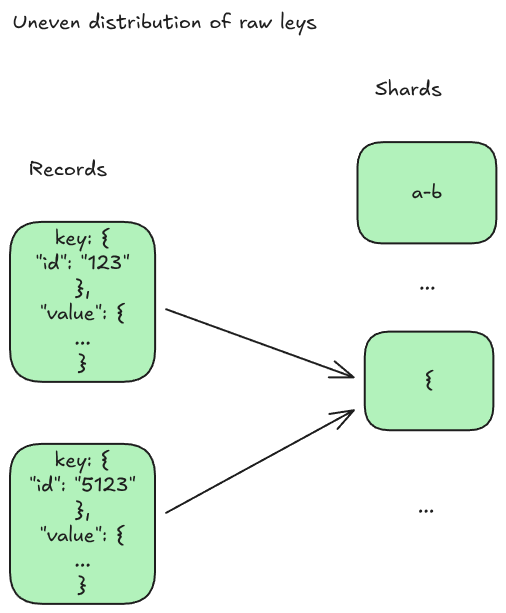
Uneven distribution of keys
One issue with using the raw key is that records would likely not be evenly distributed. This is especially true if I went with the approach of stringifying json based keys. Each key would start with a curly brace ( { ), thus putting all records on the host that contains curly brace as the prefix. To resolve this, I decided to introduce a hashing mechanism to convert the raw data into a unique string that takes into account the entire key record.
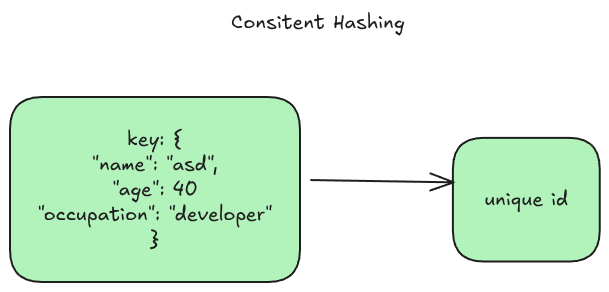
Hashing
The approach I took again was to stringify the record into a json string, but instead of using the raw string, I used a SHA256 hashing library to convert the record to a unique base64 encoded string. This method generates a (virtually) unique 64 character base64 encoded string for the input that I can then use for finding the proper shard to store and lookup records in.
This approach provided several benefits. First, this produced unique keys for each input key and lead to relatively even distribution of keys even when they started with the same prefix. Another benefit was that keys all had the same length of 64 characters vs variable length of the raw key. This is a nice benefit especially if raw keys were very long, and also ensures that keys do not exceed the 256 character file name limit of the filesystem when stored (as I used this for storing the key to disk as well). At this point we were in a good spot, but there was one more thing I needed to do to avoid has collisions.
String vs object conundrum
One last thing I needed to consider was differentiating between data types. Mainly, I needed to differentiate between strings and objects. Remember before I perform the hash, I convert objects to strings then hash. This leaves us with potential hash collisions between raw strings and the stringified objects since from the hashing process, both are interpreted as strings. The solution for this was to encode the data with a prefix indicating data types. What I mean by this is that before each value in the key, I would prefix a character indicating it’s datatype. For objects, I would prefix the data with o:, and strings would be prefixed with s:. This way, objects and strings would be differentiated, and the hashes would end up being unique, mitigating hash collisions.
Wrapping Up
So that’s basically it, not too hard. Now I have a consistent hashing library and support for sharding across multiple instances and generating unique key hashes for storage on the file system. Thanks to this, we can now find where records are located, and don’t have to store a lookup map to do so.
Keep it consistent!
J